
Habituellement, lorsqu’une nouvelle génération de cartes graphiques fait son apparition, la simple évocation d’un nombre d’unités de calcul, de valeurs de fréquences, ou de valeurs de finesse de gravure, suffisent à imaginer un gain de performances potentiel. S’agissant des produits Turing, la lecture s’annonce beaucoup plus ardue, notamment en raison d’ajouts architecturaux centrées sur les calculs d’IA ou de ray tracing.
Vous n’aurez pas manqué de le noter, NVIDIA a dû faire face à une forme de grogne de la part de ses utilisateurs habituels derrière l’annonce des GeForce RTX. En cause notamment, des spécifications traditionnelles sans doute en dessous des attentes, pour des fréquences de fonctionnement à peine augmentée par rapport à la génération précédente. Pour vous donner quelques éléments de comparaison, entre une GTX 980 Ti et une GTX 1080 Ti, le nombre de cœurs CUDA avait bondi de 28% tandis que la fréquence GPU avait pris un bonus de plus de 40%. Si l’on descend d’un niveau de gamme, et que l’on compare GTX 980 et GTX 1080, on retrouve une tendance similaire : +25% côté cœurs CUDA et +42% côté fréquence. Si l’on revient au cas qui nous intéresse aujourd’hui, la GeForce RTX 2080 Ti compte 4352 cœurs élémentaires pour une fréquence de fonctionnement maximale de 1635 MHz, soit +21% dans un cas, et un petit +7% dans l’autre. Le cas de la RTX 2080 est encore plus parlant : un saut de puce côté unités, +15%, tandis que la fréquence ne monte que de 4% face à la GTX 1080.
| GTX 1070 | RTX 2070 | GTX 1080 | RTX 2080 | GTX 1080 Ti | RTX 2080 Ti | |
|---|---|---|---|---|---|---|
| Architecture / GPU | Pascal GP104 | Turing TU106 | Pascal GP104 | Turing TU104 | Pascal GP102 | Turing TU102 |
| Process de gravure | 16 nm | 12 nm FFN | 16 nm | 12 nm FFN | 16 nm | 12 nm FFN |
| Nombre de transistors | 7.2 milliards | 10.8 milliards | 7.2 milliards | 13.6 milliards | 12 milliards | 18.6 milliards |
| Taille du die | 314 mm² | 445 mm² | 314 mm² | 545 mm² | 471 mm² | 754 mm² |
| Blocs SM | 15 | 36 | 20 | 46 | 28 | 68 |
| CUDA Core | 1920 | 2304 | 2560 | 2944 | 3584 | 4352 |
| Tensor Core | NA | 288 | NA | 368 | NA | 544 |
| RT Core | NA | 36 | NA | 46 | NA | 68 |
| ROPs | 64 | 64 | 64 | 64 | 88 | 88 |
| TMU | 120 | 144 | 160 | 184 | 224 | 272 |
| GPU Base Clock | 1506 | 1410 | 1607 | 1515 | 1480 | 1350 |
| GPU Boost Clock (*) | 1683 / 1683 | 1620 / 1710 | 1733 / 1733 | 1710 / 1800 | 1582 / 1582 | 1545 / 1635 |
| Mémoire | 8 Go GDDR5 | 8 Go GDDR6 | 8 Go GDDR5X | 8 Go GDDR6 | 11 Go GDDR5X | 11 Go GDDR6 |
| Fréquence mémoire | 8 Gbps | 14 Gbps | 10 Gbps | 14 Gbps | 11 Gbps | 14 Gbps |
| Bus mémoire | 256 bits | 256 bits | 256 bits | 256 bits | 352 bits | 352 bits |
| Tarifs de lancement (Version FE, Hors taxes) | 449$ | 599$ | 699$ | 799$ | 699$ | 1199$ |
(*Reference / Founders Edition)
A la lumière de ces premiers chiffres, on peut comprendre l’inquiétude des utilisateurs, qui ont dû se demander où étaient passés les gains liés à l’amélioration (certes légère mais quand même) de la finesse de gravure, annoncée à 12 nm. C’est tout le sel du pari technologique auquel nous faisions référence en introduction de ce dossier : contrairement aux dernières générations de GPU, les puces Turing ne font plus reposer leur force sur un schéma traditionnel défini par un nombre de cœurs CUDA, une fréquence de fonctionnement et une finesse de gravure. Elles misent sur de nouvelles formes de rendu, qui feront appel au ray tracing ou aux applications de deep learning. Des éléments, qui au moins sur le papier, ont le potentiel de contrebalancer la faiblesse des chiffres cités plus haut. Sur un plan technique, on commencera par noter que cette volonté d'évolution a obligé NVIDIA à repenser assez largement son modèle de blocs SM (pour Streaming Processor), bloc qui constitue le plus bas niveau, le cœur, des architectures GPU du fabricant.
Le SM à la sauce Turing
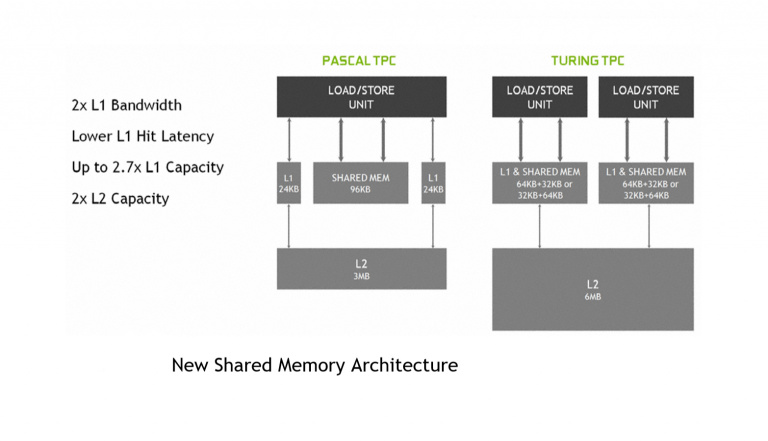
Plus concrètement, au sein des précédentes architectures Maxwell et Pascal, un bloc SM était schématisé de la manière suivante : on y trouvait 4 partitions qui chacune intégraient 32 Cœurs CUDA, un bloc SFU, des registres, 2 TMU, 8 unités Load/Store et 2 unités d’expédition associées à un tampon d’instructions. Parallèlement, tous ces éléments présentaient un certain nombre de ressources partagées à différents niveaux : 96 Kb de mémoire et un cache d’instructions pour l’ensemble, et 4 TMU et un cache L1 de 24 Ko pour chaque paire de partitions.

Sur la base de cette image, NVIDIA a opéré trois principaux changements : la fin du doublement des unités d’expédition (dispatch units), la refonte du système d’ordonnancement, qui peut maintenant gérer jusqu’à 32 threads de manière indépendante, et la séparation des deux ALU qui constituaient auparavant les fameux cœurs CUDA : tandis qu’ALU FP32 et INT32 se trouvaient rassembler au sein d’une même entité et ne pouvaient être sollicitées conjointement sous Maxwell et Pascal, elles profitent sous Turing d’une gestion complétement indépendante. Sur le schéma fourni par NVIDIA, cela se traduit par la mention de 64 Core FP32 et 64 Core INT32 par bloc SM Turing, en lieu et place des 128 cœurs CUDA sous Pascal. A cela s’ajoute un autre axe de travail : la révision du système mémoire qui rassemble maintenant au sein d’un même bloc configurable le cache de données L1 et la mémoire partagée.
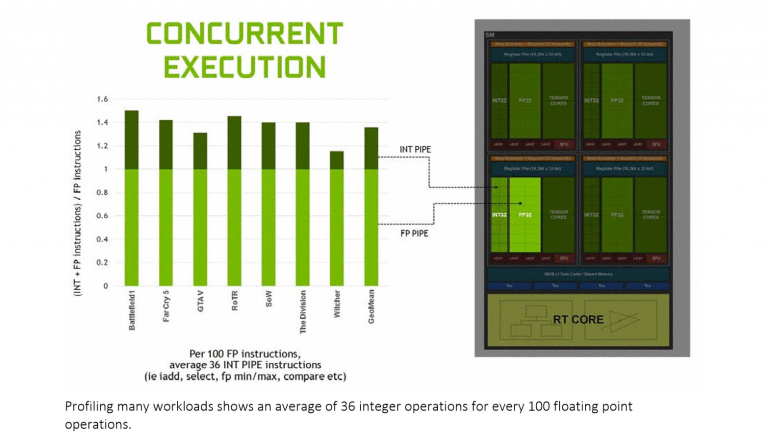
Tout cela pour quelles conséquences ? Si l’on devait résumer la chose, on pourrait avancer que la majorité de ces modifications traduisent une même volonté de revoir l’approche des calculs parallèles des GPU NVIDIA. En supprimant une unité d’expédition par SM, en autorisant l’exécution simultanée des calculs sur des entiers et des flottants, et en proposant une gestion plus fine des fils d’exécutions, NVIDIA entend conserver une efficacité en matière de calculs parallèles, tout en offrant aux développeurs plus de souplesse dans la manière dont ils peuvent exploiter les ressources GPU. Comme souvent, il faut comprendre qu’il n’y a pas dans ce qui est proposé ici de bon ou de mauvais choix. Il s’agit surtout de trouver le compromis technique qui corresponde le mieux aux usages modernes des développeurs. Et avec les possibilités offertes à ces derniers par DirectX 12, NVIDIA a choisi de s’orienter vers un modèle SIMT (Single Instruction, Multiple Thread) plus souple que celui développé sur Maxwell et Pascal. Si l’on en croit les données NVIDIA, cette nouvelle structure permettrait en tout cas d’augmenter le traitement des shaders modernes de 50%.
Système mémoire, cœurs CUDA, TMU… Jusqu’à présent, vous constaterez que nous n’avons abordé que la partie traditionnelle de la nouvelle architecture. Or, et nous l’avons souligné en introduction de cette page, Turing se caractérisera surtout par l’intégration de technologies innovantes, qui seront matérialisées par deux nouveaux types d’unités de calculs : les Tensor Core et les RT Core.
Quelques grammes de ray tracing dans un monde de rastérisation
Commençons par faire le point sur les RT Core, qui seront donc, comme leur dénomination l’indique, dédiés aux calculs ray tracing. Le ray tracing, pour ceux qui seraient passés à côté des différentes annonces conjointes de NVIDIA et Microsoft ces derniers mois, c’est un peu le Saint Graal en termes de rendu graphique. Une approche qui permettrait d’offrir à nos jeux une ambiance photoréaliste, similaire à celle que l’on retrouve dans la plupart des films d’animation modernes. Très basiquement, la technique du ray tracing consiste à projeter une somme de rayons depuis un point de vue vers un pixel, puis vers la scène 3D dont il est issu : ce faisant, certains vont ainsi rencontrer des sources de lumière, d’autres vont être stoppés par des objets, quand d’autres encore, vont rebondir dessus par réflexion, ou les traverser, avant de sortir de la scène ou de rencontrer à leur tour d’autres éléments, et ainsi de suite. C’est finalement l’analyse de l’ensemble de ces rayons et de leurs interactions qui va permettre d’ajuster la couleur des pixels afin de traduire des effets d’ombres, de lumière, de réflexions, particulièrement bluffants… Toutefois, aussi chatoyante soit-elle, la technologie ray tracing a un défaut majeur : elle est extrêmement couteuse en termes de ressources GPU, au point qu’il est impossible d’envisager un rendu de ce type en temps réel. C’est pour cela que depuis des années, la technique de rendu par excellence utilisée dans les jeux reste la rastérisation, qui se base quant à elle sur des approximations, des simulations, pour générer la géométrie d'une scène et les effets mentionnés plus haut.

Mais si le ray tracing est impossible à gérer en temps réel, pourquoi en parle-t-on ? Parce que si les GPU actuels ne sont pas suffisamment puissants pour assumer un rendu ray tracing complet, ils peuvent néanmoins ambitionner de l’apporter par petites touches. C’est tout le pari de ce que NVIDIA appelle l’approche hybride, qui va combiner au sein d’un même pipeline de rendu des éléments obtenus par rastérisation et des éléments obtenus par ray tracing, le but étant évidemment d’extraire le meilleur des deux mondes.

Ainsi, on utilisera la rastérisation pour réaliser toute la partie géométrie, tandis que la projection de rayons sera exploitée pour générer des ombres plus réalistes, ou de plus beaux effets de réflexion, le tout étant ajustable en fonction d’une expérience ciblée d’un point de vue performances. Et ce travail de ray tracing sera assigné aux fameux RT Core, qui peuvent être considérés comme des unités de calcul spécialisées, chargées de réaliser de la manière la plus efficace possible les deux types d’opérations intrinsèques au rendu ray tracing, nommées Bounding Volume Hierarchy Traversal et Ray/Triangle Intersection Testing. La première opération va consister à rechercher la primitive / le triangle qui va interagir avec un rayon au sein de la scène 3D. La seconde servira à déterminer le type d’interaction qui naitra de la rencontre objet / rayon.

Nous vous glissons ici et là quelques travaux et démonstrations sur les possibilités de ce mode de rendu hybride, mais à bien des égards, le résultat est bluffant. Maintenant, comme toutes les nouvelles technologies de rendu, son succès restera dépendant de la volonté des développeurs de vouloir l’utiliser. Et dans la mesure où les RT Core sont des unités exclusives, sans jeux intégrant des éléments de ray tracing, elles pourraient très bien rester là à dormir. Les exemples dans l’histoire des cartes graphiques ne manquent pas pour argumenter ce risque : sur la génération Pascal, la technologie SMP par exemple, qui visait à accélérer les rendus de type VR, n’a pas rencontré un succès incroyable, la faute sans aucun doute, à une adoption timide (pour être sympa) des systèmes de réalité virtuelle par le grand public.

Certes, le gain visuel que l’on peut vendre à un utilisateur final est réel dans le cas du ray tracing, mais en matière de développement d’un jeu vidéo, ce gain sera mis en balance avec des contraintes de timing, de budget, de compétences à acquérir. Pour résumer, NVIDIA fournit ici les outils… Aux développeurs maintenant de trancher sur la pertinence de les utiliser.
« Et nous nous sommes émerveillés de notre magnificence dès la venue au monde de l’IA... »
Ce qui nous amène à la seconde grosse nouveauté côté unités de calcul spécialisées : les Tensor Core. En effet, si l’exploitation des RT Core reste soumise à la bonne volonté des différents acteurs du jeu vidéo, celle des Tensor Core pourra s’en passer. Et compte tenu des services qu’ils vont pouvoir rendre, c’est un argument non négligeable en faveur des GPU Turing. Mais que sont les Tensor Core ? Ils représentent la partie matérielle de la technologie NGX (pour Neural Graphics Acceleration), une technologie qui va utiliser les principes d’intelligence artificielle pour générer certains traitements graphiques, mieux et plus rapidement que ne l’auraient fait des unités de calculs arithmétiques. NVIDIA a déjà développé plusieurs applications sur cette base : NGX InPainting va par exemple travailler sur une image endommagée pour la réparer et en créer une alternative cohérente et sans défaut visible. NGX Slow-Mo également, va là encore utiliser les principes d'IA pour donner à une vidéo classique un effet slow motion, les images manquantes étant alors créer de toute pièce. Et AI Super Rez visera à augmenter la résolution d’une image d’un facteur 2, 4 voire 8, en proposant une finesse et une précision équivalente à ce que l’on aurait obtenue sur une photo prise en natif dans cette configuration. Mais l'application qui va nous intéresser en premier lieu, parce qu'elle touchera effectivement la qualité d'un jeu vidéo (IA Super Rez, par exemple, vise à être intégré comme outil Ansel plutôt que comme alternative au traitement DSR), c'est le DLSS pour Deep Learning Super-Sampling… Une autre manière d’envisager l’anti-aliasing.

L’anti-aliasing est un vrai problème d’un point de vue rendu. En résumé, on peut difficilement s’en passer parce qu’il s’agit d’un aspect impactant fortement la qualité visuelle d’une image. Mais si on veut le faire bien, cela coute cher en ressources GPU. Il existe évidemment des alternatives plus légères, qui sont réalisées en post-traitement, mais elles ont des contreparties visuelles. C’est là qu’intervient l’IA. Encore une fois, très schématiquement, le travail de l’IA dans le cadre qui nous occupe va se caractériser par deux phases consécutives : l’une d’entrainement ou d’apprentissage et l’autre d’inférence. La première phase va avoir lieu en amont : elle consistera à faire travailler des calculateurs sur des milliers d’images de référence, chacune dans deux versions : avec une très haute qualité d’antialiasing, et sans aucun traitement. Dans notre cas, les images correspondront sans doute (nous n’avons pas eu de détails là-dessus) à des personnages, des lieux, des environnements que l’on retrouvera dans un jeu donné. L’étude des différences entre chaque duo d’images va permettre de créer un réseau neuronal, que l’on pourra assimiler à une série de règles comparatives que l’on aurait accumulées de manière empirique. Une fois l’entrainement terminé, le réseau IA est réinjecté soit au niveau du moteur de jeu, soit au niveau des pilotes, soit via GeForce Experience, afin d’être exploité par les Tensor Core : on sera alors dans la phase dite d'inférence. Il faut noter que les calculs d’IA s’apparentent à des calculs matriciels, pour lesquels les cœurs CUDA traditionnels n’étaient pas taillés. Cela explique la nécessité d’intégrer de nouvelles unités spécialisées au sein des stream processor.

Tout cela, c’est bien beau, mais quelles sont les implications d’un traitement comme le DLSS ? Eh bien, toujours sur le papier puisque nous n’avons pas encore pu tester la chose, elle semble énorme. Si l’on en juge par les quelques démonstrations qui nous ont été faites, l’utilisation du DLSS tel qu'il est actuellement défini impliquerait une qualité de rendu équivalente à un traitement TAA (Temporal Anti Aliasing) 4X. Mieux encore : sur un même jeu et à rendu équivalent, une RTX 2080 Ti exploitant le DLSS offrirait un frame rate doublé, par rapport à une GTX 1080 Ti exploitant un anti aliasing de type TAA. Un gain intrinsèque à la méthode qui, en déroutant la gestion de l'anti-aliasing sur les Tensor Core, libère de la puissance pour les calculs géométriques classiques. Enfin, l’autre avantage du traitement DLSS, comme nous le suggérions un peu plus haut, c’est qu’il peut être poussé pour chaque jeu directement au niveau des pilotes du GPU par NVIDIA. C’est ce point qui a permis à la firme d’annoncer la compatibilité du DLSS avec une quinzaine de titres fin aout, puis d’en ajouter neuf autres quelques semaines plus tard.


On comprend mieux dès lors la philosophie générale de Turing, qui va chercher à créer d’autres ressources pour gérer efficacement certains rendus, plutôt que de multiplier les fréquences de fonctionnement et les unités de calculs arithmétiques. On ne va pas se mentir, la démarche présente évidemment un risque : répétons-le parce que c'est important, NVIDIA fournit ici un certain nombre de nouveaux outils. Il appartiendra aux développeurs de déterminer s’ils souhaitent se les approprier. Toutefois, nous dirions que s’agissant des RTX 2070, 2080 et 2080 Ti, cette prise de risque profite d’un contexte particulièrement favorable, puisque ces produits n’auront certainement pas de concurrence avant plusieurs mois, voire plusieurs années, que ce soit du côté d’Intel ou d’AMD.
Toujours pas de HBM2 mais de la GDDR6
Mais laissons les stratégies commerciales de côté (nous y reviendrons), et continuons notre exploration de l’architecture Turing, en prenant un peu de recul : nous venons de faire le tour des nouveautés qui vont habiller le cœur des nouveaux GPU, voyons maintenant ce que les équipes NVIDIA nous ont réservé sur la gestion mémoire, le moteur vidéo, ou le pipeline de rendu. Fin 2017, NVIDIA lançait sa GeForce Titan V, un produit reposant sur l’architecture Volta, dont les RTX reprennent de nombreux éléments, et qui exploitait notamment une mémoire HBM2. Qu’en est-il pour les cartes Turing ? Eh bien la marque aura finalement fait le choix de la GDDR6. Un choix de raison, par rapport à l’HBM2 qui reste définitivement trop complexe et trop cher à produire. Par rapport à la GDDR5X qui équipaient les cartes GTX 1070, 1080 et 1080 Ti de la génération précédente, la nouvelle GDDR6 14 Gbps apportera un gain net de bande passante de 25 à 75% selon le bus mémoire associé. En complément, le cache L2 du GPU se voit doubler, passant de 3 à 6 Mb sur les séries 80Ti, et de 2 à 4 Mb sur les séries 70 et 80. Et à cela vont s’ajouter les gains obtenus grâce à des algorithmes de compression toujours plus aboutis.

Côté moteur d’affichage, les GeForce continuent également leur évolution en vue d’être prêtes à gérer les standards visuels de demain. Les RTX pourront ainsi supporter la norme DisplayPort 1.4a, qui va permettre de pousser l’affichage sur 8K en 60 Hz sur deux écrans. On note à ce propos que NVIDIA a ajouté sur le bracket arrière des GeForce RTX une nouvelle sortie de type USB-C, et renommée Virtual-link. Elle permettra de dégager 4 lignes HBR3 DP, ce qui pourra notamment faciliter le branchement des casques de réalité virtuelle, qui n’auront dès lors besoin que d’une seule liaison câblée pour l’ensemble de leurs besoins. Enfin, l’encodage et le décodage vidéo ne sont pas en reste : l’encodeur NVENC intègre le support de l’H.265 (HEVC) en 8K / 30 FPS tandis que la partie NVDEC s’enrichit des supports suivants : HEVC 10/12b HDR à 30 FPS, H.264 8K, et VP9 10/12b HD.

En avons-nous terminé avec les nouveautés apportées par cette génération Turing ? Pas tout à fait. Derrière les innovations matérielles, NVIDIA a également cherché à optimiser son pipeline de rendu, en y appliquant quelques modifications qui auront pour but de simplifier le travail des développeurs, et/ou de leur apporter une certaine souplesse vis-à-vis de leurs opérations de rendu. Par exemple, le Mesh Shading entend apporter une solution au fameux problème des draw calls dans le jeu vidéo, problème auquel DirectX 12 devait apporter un début de solution. Pour résumer, le pipeline de rendu actuellement utilisé est très efficace lorsqu'il s'agit de travailler sur les détails d'un objet, mais avec l'augmentation de la puissance graphique disponible, les scènes 3D sont devenus de plus en plus riches, et les objets à traiter se sont multipliés de manière exponentielle. Or, chacun de ses traitements impliquent des interactions avec le processeur, et ce dernier peut rapidement se retrouver surchargé, devenant un facteur limitant au sein du processus de rendu. Face à cette situation, le Mesh Shading consiste à autoriser le traitement de groupe d'objets, dont les caractéristiques sont similaires. NVIDIA donne notamment l'exemple d'un champ d'astéroïdes au sein d'une scène spatiale : plutôt que de définir le niveau de détail appliqué à chaque objet en fonction de sa distance d'affichage, le développeur pourra créer des listes, qui seront alors traités comme telles par le CPU, ce qui réduira significativement le nombre de draw calls généré.
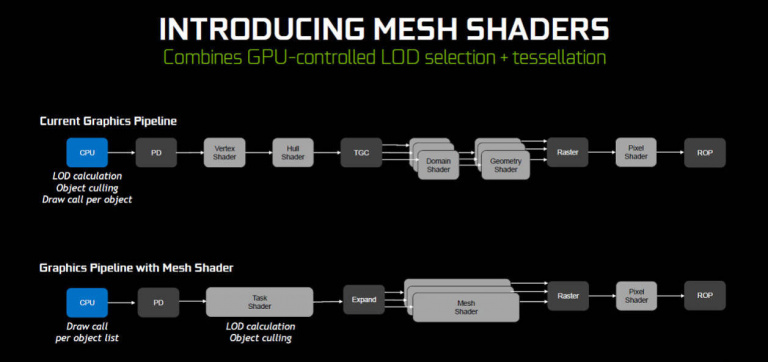

Dans le même esprit, la technologie dite VRS pour Variable Rate Shading va permettre aux développeurs de définir pour certaines zones de l'image des qualités de rendu différentes. Ils pourront alors choisir d'économiser des ressources GPU sur des calculs qui n'auraient pas eu un impact significatif sur l'aspect visuel. Une technique que NVIDIA avait d'ailleurs déjà expérimentée dans le cadre des applications VR, où des algorithmes venaient adapter la qualité de rendu entre la zone centrale de l'image et les zones périphériques. Cela s'appelait alors le Multi-Res Shading. Enfin, dernier raffinement proposé par les équipes des verts aux développeurs : le TSS pour Texture Space Shading. Là, encore, on cherche à économiser les ressources GPU, en permettant de conserver en mémoire certains traitements récurrents, afin de pouvoir les réexploiter dans le cadre d'un nouveau process de rendu. Le cas d'école pour ce type d'optimisation serait évidemment la VR, qui demande à générer en permanence deux images quasiment identiques. On notera cependant une nouvelle fois (mais c'est important) que NVIDIA fournit ces outils via sa bibliothèque GameWorks. Il appartiendra aux studios de les exploiter... Ou pas.

Vous l'aurez compris à la lecture de l'ensemble de ces fonctionnalités, Turing est réellement une architecture très particulière, sans doute plus que ne l'avait été Maxwell ou Pascal (pour celles que nous avons eu l'occasion de tester en détail). Et les cartes qui vont les porter ne le seront pas moins, comme vous allez le voir dans la page qui suit.